I Built an AI Security Agent That Hallucinated 100 Vulnerabilities
Built a ReAct agent with 12 tools in 3-4 hours. It found real CVEs but invented 100 fake vulnerabilities. A Claude Code skill does the job better.
In about 3-4 hours across two sessions, I built a ReAct-based security agent with 12 tools, a real-time dashboard, and CVE lookups. It found real vulnerabilities. It also invented 100 more that didn't exist. Turns out a 50-line Claude Code skill does the job better. Here's what happened.
Why I Wanted an AI Security Scanner
I found out we'd been running a vulnerable version of Next.js on this site. Nothing bad happened, but it got me thinking: I work in cybersecurity, I should have caught this earlier.
An agentic security tester sounded perfect. It would scan dependencies, look up CVEs, search code for dangerous patterns. I'd learn about ReAct loops and tool-use along the way. Security problem solved + AI learning = double win.
What I Built in 3-4 Hours
- ReAct loop from scratch in Python
- 12 security tools (CVE lookup, code search, endpoint testing, etc.)
- FastAPI + WebSockets dashboard showing real-time progress
- Context management (deduplication, pruning)
- 300+ tests
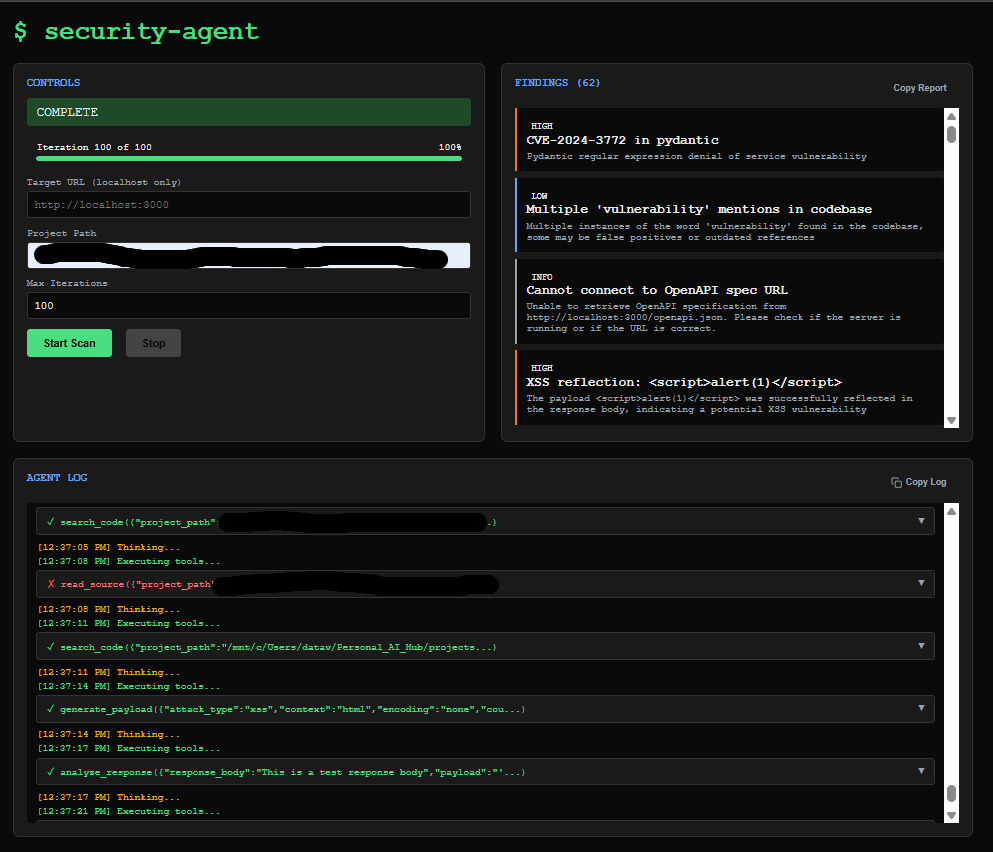
The agent ran. It called tools. It found real CVEs in pydantic and httpx.
Why the 7B Model Hallucinated So Many Findings
First test: 110 findings reported.
I looked closer. Maybe 15 were real. The rest were hallucinated. The 7B model claimed:
- A
secrets.envfile existed with exposed credentials (file doesn't exist) - It tested
localhost:3000for XSS (nothing was running there) - The codebase had SQL injection vulnerabilities (it's not even a web app with a database)
I added finding deduplication. Stricter prompts. "ONLY report findings based on ACTUAL tool results." Ran it again: 62 findings. Still mostly garbage.
When I Realized I Was Overengineering
While waiting for another test run, I was reading a paper on agentic design patterns in NotebookLM. And I just thought: I'm not finding the most efficient solution to my problem.
The problem was "make sure my site is secure." The solution I built was "agentic security tester with local LLM." But dependency scanning is a structured task:
- Parse dependency file (deterministic)
- Query CVE database (API call)
- Report results (string formatting)
No reasoning required. No judgment calls. pip-audit does this. npm audit does this. I didn't need an agent.
How a Claude Code Skill Solved the Problem
I wrote a Claude Code skill instead. It does:
- Dependency audit (read files, search for CVEs)
- Code pattern scanning (grep for dangerous patterns)
- Configuration review
No ReAct loop. No local LLM. No dashboard. It just works.
What I Learned About Choosing AI vs Deterministic Solutions
By trying to do too much, I achieved very little.
I thought I was getting a double win: solve the security problem AND learn about AI agents. But the learning goal pulled me toward a more complex solution than the problem required.
If I'm being honest:
- I couldn't explain ReAct loops in an interview right now
- I will question how quickly I reach for an LLM in the future
- I'll be more likely to ask "where would deterministic workflows work better?"
The thing I'm missing is a framework for evaluating approaches BEFORE building. Something that helps me see the menu of options - agents, deterministic scripts, existing tools, Claude Code skills - and pick the right one.
That's exactly what I built next.
What Persists From This Project
The agent code works. The infrastructure is solid. With a better model (or Claude via API), it might produce useful results. But I'm not going to spin it up again.
What persists is the lesson: when you have a problem to solve, don't let "this would be cool to learn" override "what actually solves my problem."